
Gradient Boosting Machine (GBM)은 앙상블 학습(Ensemble Learning) 기법의 하나로, 여러 개의 약한 학습기(weak learner)를 결합하여 예측 성능을 향상시키는 방법입니다. 주로 결정 트리(Decision Tree)를 사용하며, 각 트리가 순차적으로 학습됩니다.
1. GBM의 정의
GBM의 핵심 아이디어는 이전 모델의 오차(residual)를 줄이는 방향으로 새로운 모델을 학습시키는 것입니다. 이 과정에서 Gradient Descent(경사 하강법)을 사용하여, GBM은 각 반복에서 손실 함수의 기울기(gradient)를 계산하고, 다음 트리는 이 기울기를 줄이는 방향으로 학습합니다.
수학적으로 정의하면 다음과 같습니다.

여기서,

이 과정은 지정된 반복 횟수나 오차가 최소화될 때까지 진행됩니다.
2. 주요 특징
1) 순차적 학습 (Sequential Learning)
첫 번째 모델이 학습한 뒤, 오차(residual)를 계산하고, 다음 모델은 이 오차를 줄이는 방향으로 학습합니다.
2) 경사 하강법(Gradient Descent) 최적화
각 트리는 오차의 경사를 계산해 그 값을 최소화하도록 학습됩니다.
3) 약한 학습기의 사용 (Weak Learner)
주로 얕은 결정 트리(depth=1~3)를 사용합니다.
3.GBM의 장점
1) 높은 예측 성능
순차적 학습을 통해 예측 오류를 점진적으로 줄여, 정확도가 높은 모델을 생성합니다.
2) 비선형 관계 학습 가능
결
-
- 정 트리 기반이기 때문에 복잡한 데이터의 비선형 패턴도 잘 학습합니다.
3) 유연성
회귀와 분류 문제 모두에 사용 가능하며, 다양한 손실 함수(예: MSE, Cross-Entropy)를 지원합니다.
4) 특성 중요도 제공
모델 학습 후 특성 중요도(feature importance)를 추출할 수 있어, 어떤 변수가 중요한지 파악할 수 있습니다.
5) 잡음(Noise)에 대한 내성
결정 트리 기반이므로 일부 잡음이 있는 데이터에서도 비교적 안정적인 성능을 보입니다.
3.GBM의 단점
1) 느린 학습 속도
순차적으로 학습되기 때문에 병렬 처리가 어렵고, 학습 시간이 오래 걸릴 수 있습니다.
2) 과적합(Overfitting) 위험
트리의 개수가 너무 많거나 깊이가 깊으면 훈련 데이터에 과적합될 수 있습니다.
3) 하이퍼파라미터 튜닝이 복잡
최적의 성능을 위해 학습률(learning rate), 트리 개수(n_estimators), 트리 깊이(max_depth) 등 여러 하이퍼파라미터를 조정해야 합니다.
4) 해석이 어려움
여러 개의 트리가 결합된 결과물이기 때문에 예측 결과를 직관적으로 해석하기 어렵습니다.
5) 병렬 처리 어려움
순차적으로 트리를 학습해야 하므로 병렬화가 어려워 대용량 데이터셋에서는 성능이 저하될 수 있습니다.
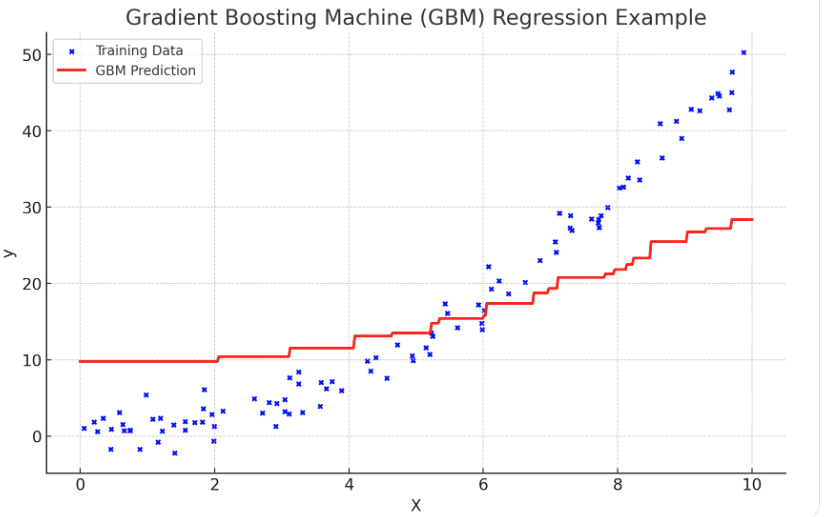
3. GBM 코드 사용 예시
# GBM 예시 코드: 회귀 문제 해결
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
# 1. 데이터 생성 (y = 0.5 * x^2 + noise)
np.random.seed(42)
X = np.random.rand(100, 1) * 10 # 0에서 10 사이의 난수 100개
y = 0.5 * X**2 + np.random.randn(100, 1) * 5 # 2차 함수 + 노이즈
# 2. Gradient Boosting Regressor 모델 생성 및 학습
gbr = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
gbr.fit(X, y.ravel())
# 3. 예측 값 생성 (훈련 데이터와 예측 값 비교)
X_test = np.linspace(0, 10, 500).reshape(-1, 1) # 테스트 데이터 생성
y_pred = gbr.predict(X_test)
# 4. 예측 성능 평가 (평균 제곱 오차)
mse = mean_squared_error(y, gbr.predict(X))
# 5. 그래프 시각화
plt.figure(figsize=(10, 6))
# 원본 데이터와 예측 값 표시
plt.scatter(X, y, color="blue", label="Training Data", s=10) # 훈련 데이터
plt.plot(X_test, y_pred, color="red", linewidth=2, label="GBM Prediction") # 예측 곡선
# 그래프 설정
plt.title(f"Gradient Boosting Regression (MSE: {mse:.2f})")
plt.xlabel("X")
plt.ylabel("y")
plt.legend()
plt.show()
'IT > ML_용어' 카테고리의 다른 글
| [ML][용어] tanh 함수(하이퍼볼릭 탄젠트 함수) (0) | 2025.10.10 |
|---|---|
| [ML][용어] One-Hot Encoding (원-핫 인코딩) (0) | 2024.10.25 |
| [ML][용어] ReLU 함수 (2) | 2024.10.15 |
| [ML][용어] Sigmoid 함수 (1) | 2024.10.11 |
| [ML][용어] GELU 함수 (1) | 2024.10.07 |




댓글